
Spark离线处理去重问题不难,把所有历史数据读进内存,然后使用Spark的各种操作算子进行统计去重即可。但是实时流计算就没那么方便了,经过一段时间的研究,摸索出了两种可供参考的方法,如下。
数据量小的情况下,读取所有的数据唯一标识符
比如已有100万手机设备的数据,现在有一个设备信息进来,如何判断这个设备数据是新用户还是旧用户。我们选取IMEI这个唯一标识来辨别设备,先把这100万的设备IMEI全部用Spark读取进来,然后实时与这个新的设备信息进行匹配,便可得知是新设备还是旧设备(在没有大数据处理框架之前,这个匹配工作是由数据库(Mysql)执行查询SQL语句来完成)。
这个思路与离线计算统计去重基本一致,但是Spark需要维护这个庞大的历史设备信息库,如果有一个新增设备,要立即加到历史设备信息库上去。随着时间的推移,这个维护量也会越来越大。
数据量很庞大的情况下
如果历史设备信息已经很庞大,比如已经超过1000万,这时再继续维护一个IMEI库就会有巨大的内存开销,既然每个IMEI都不一样,那么我们是不是可以转换一种思路,通过一种hash算法将每个IMEI映射成一个整数,然后再构造一个巨大的 bitmap 表,通过 bitmap 表的一个位(bit)来对应这个整数,熟悉 bitmap 算法的人都知道,这种去重方法是非常节约内存的。一个 bit 位即代表一个设备,通过查找这个位的值为1还是0来判别是否新设备。(1是旧设备,0是新设备)
如果使用 Scala 构造一个10万整数的数组,可以表达 10万 * 32 = 320 万设备信息(一个整数类型拥有32位)。而这10万数组占用320万/8 = 40万个字节,40万/1024/1024 = 0.38 M,不到0.4M的内存占用,可以说是非常高效了。即使数据量以亿为量级,内存占用也不过几十M而已
再回到之前提到的hash算法,也的确是存在这种字符串到整数的哈希算法的,而且还不止一种,经过多方测评,其中的BKDRHash算法最为优秀,详情可以参考 https://blog.csdn.net/hzhsan/article/details/25552153?utm_source=blogxgwz1
下面使用Scala对 bitmap 算法进行具体实现
沿袭数组索引从0开始的惯例,我们也使用第1位留空,第2位才表示设备1,第3位表示设备2,依次类推。设备编号即为这个bit位的索引。举个栗子,如果一个设备的IMEI(不一定必须IMEI,也可以是其他参数),通过BKDRHash算法映射到了1001这个整数,那么这个数组从左往右数第1002位便表示这个设备。
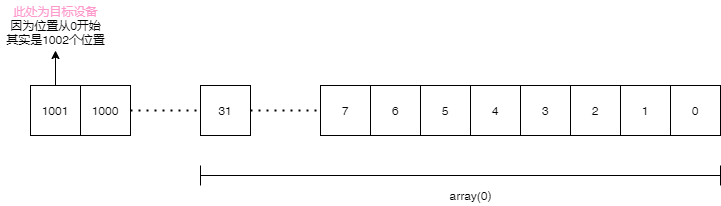
因为像 Scala 这样的高级语言,并没有直接提供数组内单个位的索引功能,只提供通过 arr(0) arr(1) 这样对数组元素的访问机制,也就是说只提供以32位为单位的一个索引功能。接下来要做的第一件事就是确定目标位在数组中的索引index是多少
从图中可以看出,array(0) 可以表示整数 0 – 31
array(1) 表示 32 – 63 array(2) 表示 64 – 95
可以看出以32为一个单位,目标整数除以32取整即可得到这个index值
(1001/32).toInt 为 31,所以这个整数落在array(31)内
接下来计算1001在array(31)内的偏移量。这个偏移量其实就是对32取模之后的值,1001 % 32 = 9 。然后进行位移 1 << 9,找到了这个位置,就可以对其进行位运算。所以最后的置1位运算公式看起来是
转换成位运算符等同于
arr(n >> 5) |= 1 << (n & 0x1F)上面是设置这个位的操作,还有查询这个位的操作
(arr(n>>5) & (1<<(n&0X1F))) != 0如果为true,表示该位已被设置,应用层则表示该设备是旧设备,否则为false,为新增设备
重置位操作
arr(n>>5) &= (~(1<<(n&0X1F)))以上便是实时去重的全部思路,如果读者有更好的实现方案,欢迎探讨。


近期评论